The objective of this lab was to learn to use ArcGIS to perform dasymetric mapping, which is a technique for allocating data from one set of boundaries to another. In this lab we learn to use a common example in which data is allocated from census units to another set of boundaries, in this case school zones. We start by calculating an estimate of high school students population based on the population of children aged 5-14 by using areal weighting, and then do the same analysis using dasymetric mapping.
First, we are provided with county and census block data, as well as data for the Manatee river basin. We quickly see that some of the census blocks are partially within and outside the river basin, but we want the population just of the river basin. To do this, we use areal weighting. An assumption made is that population is distributed evenly within each block group. Areal weighting is basically taking the population of a census block and, using the percentage of that block within the river basin, calculating the population of that block that is within the basin. For example, a block 30% within the basin with a population of 200 will have a new population of 60 within the basin.
In the second part of the lab, I started working with the data to be used the rest of the lab. The objective was to used the population aged 5-14 to predict the upcoming high school attendance. Our data layers are census tracts, water polygons, and high school boundaries. We can assume that the population is equally distributed in areas outside the water polygons. The trick here was determining the area before and after the polygons are joined. Before any overlay is done, I added a field for area and calculated the area of each census block. Then I clipped both the high schools layer and the hydro layer to the extent of the census blocks. I also clipped the hydro clip and the original census layers to the extent of the high school clip in an attempt to avoid "slivers", which could affect my population estimate. I used the Union tool to combine all 3 layers, created a new area field, and calculated the area. Next I created 4 new population fields (one for each original population field) and used the equation provided to calculate the new population. The equation is:
new population = original population * (area after / area before).
So this is simply an adjustment in the population based on the ratio of the area within the school zones. To calculate the error, I used provided reference population values and compared them to values determined by my areal weighted estimate. To calculate the overall accuracy, I used the equation:
Sum of Abs(Error) / Sum (reference population) * 100.
Based on this, the total % of people aged 5-14 allocated incorrectly was 11.6%.
In the next portion of the lab, we were to use dasymetric mapping to see if we could decrease the % allocated incorrectly. To me, this was a very confusing concept, but I think I have the concept (if not the correct values) at the end. In addition to the data from the previous section, we are provided with a 30 m x 30 m raster of imperviousness values. Impervious objects are objects that are covered by impervious features (i.e. concrete, asphalt, etc). Generally as the % imperviousness increases, so does the population, so we can use this as ancillary data to try to better predict the high school populations. Based both on what is said in this lab and on reading papers about it, we can safely assume a linear relationship between imperviousness and population. I knew that I wanted to do the same type of calculation as with the areal weighting, but was not sure for the longest time how to determine the new imperviousness. Using the Zonal Statistics as Table tool, I was able to obtain the information I needed from the imperviousness raster, specifically the Count, the Mean, and the Sum. After joining this with the census data, the count value is the number of pixels in that tract, the mean is the average imperviousness per census tract, and the sum is the mean * count. I performed an intersect using this layer and the high schools layer, which is where I was stuck for a while. I finally realized that since the census tracts are getting broken up into school zones, wherever they don't "fit" perfectly (where portions of a census block are in multiple school zones), I have multiple values for that census tract. To determine the new imperviousness, I selected each census block and calculated the new imperviousness by dividing the original imperviousness by the number of school zones each is broken up into. Based on that, I was able to calculate the imperviousness weighted estimate using the equation:
new population = original population (new imperviousness / original imperviousness).
After calculating my overall accuracy, using imperviousness leads to a misallocation of students of 11.9%. I am questioning these results however, because I believe that imperviouness should reduce the % misallocation of population. It is possible my methodology or math is incorrect as this was a complicated topic, and I'm still not sure I fully understand its application. It took a lot of trying different kinds of overlay before I figured out the correct methodology. Based on my results, it appeared that the imperviousness definitely reduces the % of incorrectly allocated students in school zones that have larger census blocks in them, especially if the tracts are broken up less by the school zones.
Monday, December 7, 2015
Friday, December 4, 2015
GIS Portfolio
As one of our final assignments for the GIS certification program, we were tasked with creating a GIS Portfolio, which is uploaded here. Additionally, I have created an audio portfolio, also uploaded here. I feel that throughout the coursework, I have a better understanding of how to create a map, considering what I am trying to convey to the map reader. I also learned how to use various color schemes and symbologies effectively and how to use different types of input (shapefiles, aerial imagery, satellite data) to create effective maps. I learned a lot during the course of this certification program and feel prepared to use these techniques throughout my career.
GIS Portfolio (PDF)
https://drive.google.com/file/d/0B6JDrUuVfdOhSGhZUVFnZ0dGSjA/view?usp=sharing
GIS Portfolio (Audio)
https://drive.google.com/file/d/0B6JDrUuVfdOhTmZOYjZhOVJhLUk/view?usp=sharing
GIS Portfolio (PDF)
https://drive.google.com/file/d/0B6JDrUuVfdOhSGhZUVFnZ0dGSjA/view?usp=sharing
GIS Portfolio (Audio)
https://drive.google.com/file/d/0B6JDrUuVfdOhTmZOYjZhOVJhLUk/view?usp=sharing
Monday, November 30, 2015
Lab 14 - Spatial Data Aggregation
The main objective of this lab was to become familiar with the Modifiable Area Unit Problem (MAUP), to analyze relationships between variables for multiple geographic units, and to examine political redistricting, keeping the MAUP in mind.
The MAUP is impacted by two components: the scale effect and the zonation effect. The scale effect is attributed to the variation in numerical results owing strictly to the number of areal units used in the analysis. The zonation effect is attributed to the variation in numerical results owing strictly to the manner in which a larger number of smaller areal units are grouped into a smaller number of larger areal units.
First, we were to examine the relationship between poverty and race using different geographic units, ranging from large numbers of small in area units (original block groups) to small numbers of units large in geographic area (House voting districts and counties). After doing this, the general pattern was that lower poverty percentages correlated with a small percentage of non-white residents. As the percentage of non-white residents, the poverty level tended to increase. As discussed in the lecture and readings, the correlation increased with smaller sample size as demonstrated by the increase in the R-square values. Not only can the number of polygons change the results, but also the area that each polygon covers can change the numerical results when comparing the census variables. The key to minimizing the impact of the MAUP on any analysis is to be consistent both in the geographical size and the number of areal units used.
Next we investigated the MAUP in the context of gerrymandering, which is to manipulate district boundaries in order to favor one political party or another. We wanted to determine which existing congressional districts deviate from an ideal boundary (i.e. which have been drawn in the context of gerrymandering the most) based on two criteria: 1) Compactness, i.e. minimizing bizarre shaped legislative districts, and 2) Community, i.e. minimizing dividing counties into multiple districts.


The MAUP is impacted by two components: the scale effect and the zonation effect. The scale effect is attributed to the variation in numerical results owing strictly to the number of areal units used in the analysis. The zonation effect is attributed to the variation in numerical results owing strictly to the manner in which a larger number of smaller areal units are grouped into a smaller number of larger areal units.
First, we were to examine the relationship between poverty and race using different geographic units, ranging from large numbers of small in area units (original block groups) to small numbers of units large in geographic area (House voting districts and counties). After doing this, the general pattern was that lower poverty percentages correlated with a small percentage of non-white residents. As the percentage of non-white residents, the poverty level tended to increase. As discussed in the lecture and readings, the correlation increased with smaller sample size as demonstrated by the increase in the R-square values. Not only can the number of polygons change the results, but also the area that each polygon covers can change the numerical results when comparing the census variables. The key to minimizing the impact of the MAUP on any analysis is to be consistent both in the geographical size and the number of areal units used.
Next we investigated the MAUP in the context of gerrymandering, which is to manipulate district boundaries in order to favor one political party or another. We wanted to determine which existing congressional districts deviate from an ideal boundary (i.e. which have been drawn in the context of gerrymandering the most) based on two criteria: 1) Compactness, i.e. minimizing bizarre shaped legislative districts, and 2) Community, i.e. minimizing dividing counties into multiple districts.
To measure compactness, I found a “compactness ratio” online that describes
compactness as the area divided by the square of the perimeter. After doing
this in ArcGIS, I see that values with a higher compactness ratio are districts
that have a more geometric shape (i.e. rectangles and squares) and those with
lower values are abnormally shaped districts. The compactness ratio seems to be
a 2D version of the isoperimetric inequality, which is a geometric inequality
relating the square of the circumference of a closed curve in a plane and the
area of the plane it encloses. Larger ratio values describe a smooth or
contiguous shape. For example, the rectangular state of Wyoming appears to be
one congressional district and has one of the highest values for “compactness
ratio”. An example of one of the "least compact" districts seen below.
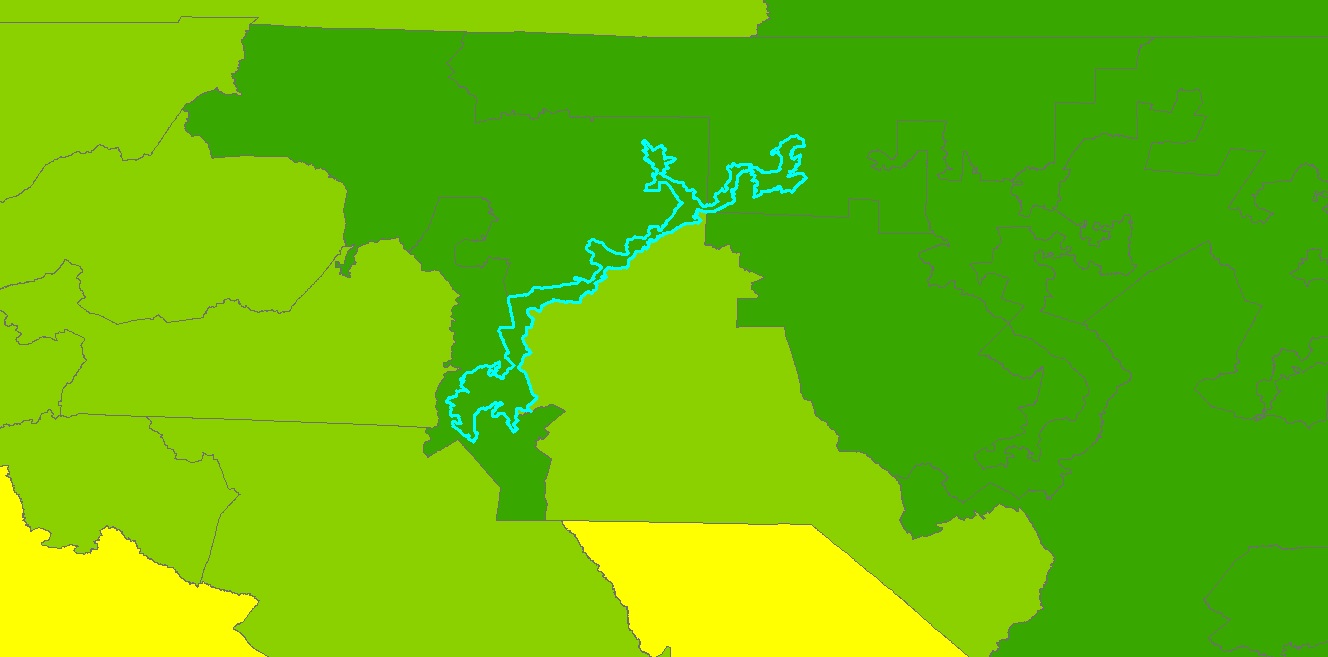
As you can see, this district is a bizarre shape. It's very long and skinny and has a lot of curves, kinks, and strangely shaped boundaries.
To measure community, I want to find areas in which one district encompasses an
entire county, not necessarily only that county, but we want counties that are
not broken up by congressional district boundaries. I had trouble with this part, as I was able to determine the number of districts within each county using a union and a spatial join, which shows the extent to which some counties are broken up into several districts, but I'm not sure this is the entire answer. Below is an image of Los Angeles County, CA, the county with the most congressional districts (24).

Friday, November 27, 2015
GIS Day Activities
I was working at my internship location as well as at least one other person in the internship program and did not get to attend a GIS day event. I don't think there were any nearby anyway. I was able, however, to lead a discussion/presentation on the current progress of the GIS project that I am doing. For the state of Arizona, I have merged crop data (location, type of crop, type of irrigation) provided by the USGS into one large dataset, to which I have added the temperature that a crop will be damaged due to a freeze (heat damage temperature is also in the dataset). The objective is to create a risk assessment that eventually can be used as part of a National Weather Service forecast. Hopefully, once a working model is developed, the idea can be pushed up the hierarchy to the regional or national level. We have had some issues getting it to work with using the proper coordinate system, but actually QGIS handles this problem better than ArcGIS, surprisingly. Additionally, we want to go that route anyway, as many don't have an ESRI ArcGIS license (too expensive and QGIS is free). The presentation on GIS Day detailed some of that and I found that the merged dataset is really helpful to the USGS community as well, as they do not have all this data in one place, which also surprised me. The data I added to their dataset (the crop temperature and rainfall needed data) came from USGS and a website I found called EcoCrop, originally developed by the Food and Agriculture Organization (FAO) of the United States. The location of crops was originally determined via satellite imagery and later double-checked by USGS personnel on the ground. People seem to be pleased with the progress made so far, and it will be up to the rest of the team to finish getting the temperature data loading properly with QGIS to finish up the risk assessment project.
Monday, November 23, 2015
Lab 13 - Effects of Scale
This lab introduced us to the effects of scale and resolution on spatial data properties. In the first part of the lab, we investigate vector data (hydro features) and in the second part we do this for raster data (elevation models).
Working with the vector data, we were provided with flow lines and water bodies at 3 different scales and at resolutions. After determining the total lengths of the lines at the 3 scales and the information about the water bodies polygons, I determined that basically, the smaller the scale, the more geographic extent is shown, but in less detail. It makes a bit more sense to me to think of it in representative fractions than verbally. 1:1200 means 1 inch on a map represents 1200 inches in the real world. You can get more detail on that than a 1:100000 map with 1 inch representing 100000 inches. I also found it interesting how the lengths, area, and perimeter of our spatial data changed with the change of scale.
In the second part of the lab, we investigated the effects of resolution on raster data. Using the original 1 m LiDAR data, we needed to resample it to create DEMs with different resolutions by changing the cell size. Determining the best resampling technique took some thought. I chose based on the type of data it is and the method I thought would maintain the elevation and slope characteristics the best. I thought the most interesting part of this was starting with the original 1 m LiDAR DEM and resampling the data to change the cell sizes, and watching the DEM have less and less detail as the cell size increased. Using the 90 m LiDAR DEM I created and the SRTM 90 m DEM I projected, I wanted to compare them in terms of their elevation values and derivatives. For this, I mainly followed the example in the S Kienzle (2004) paper, "The effect of DEM raster resolution on first order, second order and compound terrain derivatives." I investigated the difference in elevation between the two DEMs, the slope (first order derivative), the aspect (first order derivative), the profile and plan curvatures (second order derivatives), and the combined curvature (compound derivative, a combination of the second order derivatives). I'm used to the mathematical definition of derivative, which is a slope of a curve (geometric) or a rate of change (physical), and both uses are really seen here. This is why the curvatures made sense to me as the rate of change of the slope (the second derivative).
Before I got to the results, I needed to recall how the LiDAR and the SRTM DEMs were created. SRTM elevation data is created using synthetic aperture radar (SAR). This uses two radar images and uses the phase difference measurements with a small base to height ratio to measure topography. Wavelengths in the cm to m range are very accurate as most of the signal is bounced back. Heavily vegetated areas may not allow the radar to penetrate enough to get accurate elevation values and very smooth surfaces such as water may scatter the radar beam so elevation values can be inaccurate or unobtainable. LiDAR elevation data is created by an aircraft flying overhead transmitting a signal to the ground and determining the time it takes for the signal to be bounced back to the transmitter, which is then used to calculate an elevation value. LiDAR also has problems in heavily vegetated areas, but there are usually enough data points to interpolate pretty accurate elevation values. Additionally, there can be up to 5 returns per pulse, so this handles rougher and heavily vegetated areas better than SRTM does.
I used ArcGIS to create the slope, aspect, and curvature layers, which I then visually compared. Based on the way the slope is flatter where the streams are but how it quickly becomes steep on either side of the stream, it seems to me this could be an area where a stream cuts through a canyon before reaching the outlet. The SRTM DEM tended to have elevation values that were higher than those of the LiDAR DEM in lower elevations (streams) and lower values in higher elevations, so the mean slope of the SRTM DEM was less than that of the LiDAR DEM. I used other images to analyze the data as well, but below is a screenshot of the slope. We can see that the maximum slope of the LiDAR DEM is greater than that of the SRTM DEM.
 I wanted to follow the example in the paper further and compare both to original point data to determine the accuracy of the two DEMs, but I did not have known elevation data. I considered using the 1 m resolution DEM as known data (the paper we read did something similar), but was not sure that would work in this case. Based on what I know about how the LiDAR and SRTM data are obtained, I think that the LiDAR data is likely more accurate, as there are more data points with less distance between them than for the SRTM data. Also, LiDAR does not have the problems over water or heavy canopied vegetation that SRTM data does. The big limitation for both is that due to how they collect data, neither can work effectively through clouds.
I wanted to follow the example in the paper further and compare both to original point data to determine the accuracy of the two DEMs, but I did not have known elevation data. I considered using the 1 m resolution DEM as known data (the paper we read did something similar), but was not sure that would work in this case. Based on what I know about how the LiDAR and SRTM data are obtained, I think that the LiDAR data is likely more accurate, as there are more data points with less distance between them than for the SRTM data. Also, LiDAR does not have the problems over water or heavy canopied vegetation that SRTM data does. The big limitation for both is that due to how they collect data, neither can work effectively through clouds.
Working with the vector data, we were provided with flow lines and water bodies at 3 different scales and at resolutions. After determining the total lengths of the lines at the 3 scales and the information about the water bodies polygons, I determined that basically, the smaller the scale, the more geographic extent is shown, but in less detail. It makes a bit more sense to me to think of it in representative fractions than verbally. 1:1200 means 1 inch on a map represents 1200 inches in the real world. You can get more detail on that than a 1:100000 map with 1 inch representing 100000 inches. I also found it interesting how the lengths, area, and perimeter of our spatial data changed with the change of scale.
In the second part of the lab, we investigated the effects of resolution on raster data. Using the original 1 m LiDAR data, we needed to resample it to create DEMs with different resolutions by changing the cell size. Determining the best resampling technique took some thought. I chose based on the type of data it is and the method I thought would maintain the elevation and slope characteristics the best. I thought the most interesting part of this was starting with the original 1 m LiDAR DEM and resampling the data to change the cell sizes, and watching the DEM have less and less detail as the cell size increased. Using the 90 m LiDAR DEM I created and the SRTM 90 m DEM I projected, I wanted to compare them in terms of their elevation values and derivatives. For this, I mainly followed the example in the S Kienzle (2004) paper, "The effect of DEM raster resolution on first order, second order and compound terrain derivatives." I investigated the difference in elevation between the two DEMs, the slope (first order derivative), the aspect (first order derivative), the profile and plan curvatures (second order derivatives), and the combined curvature (compound derivative, a combination of the second order derivatives). I'm used to the mathematical definition of derivative, which is a slope of a curve (geometric) or a rate of change (physical), and both uses are really seen here. This is why the curvatures made sense to me as the rate of change of the slope (the second derivative).
Before I got to the results, I needed to recall how the LiDAR and the SRTM DEMs were created. SRTM elevation data is created using synthetic aperture radar (SAR). This uses two radar images and uses the phase difference measurements with a small base to height ratio to measure topography. Wavelengths in the cm to m range are very accurate as most of the signal is bounced back. Heavily vegetated areas may not allow the radar to penetrate enough to get accurate elevation values and very smooth surfaces such as water may scatter the radar beam so elevation values can be inaccurate or unobtainable. LiDAR elevation data is created by an aircraft flying overhead transmitting a signal to the ground and determining the time it takes for the signal to be bounced back to the transmitter, which is then used to calculate an elevation value. LiDAR also has problems in heavily vegetated areas, but there are usually enough data points to interpolate pretty accurate elevation values. Additionally, there can be up to 5 returns per pulse, so this handles rougher and heavily vegetated areas better than SRTM does.
I used ArcGIS to create the slope, aspect, and curvature layers, which I then visually compared. Based on the way the slope is flatter where the streams are but how it quickly becomes steep on either side of the stream, it seems to me this could be an area where a stream cuts through a canyon before reaching the outlet. The SRTM DEM tended to have elevation values that were higher than those of the LiDAR DEM in lower elevations (streams) and lower values in higher elevations, so the mean slope of the SRTM DEM was less than that of the LiDAR DEM. I used other images to analyze the data as well, but below is a screenshot of the slope. We can see that the maximum slope of the LiDAR DEM is greater than that of the SRTM DEM.

Monday, November 16, 2015
Lab 12 - Geographically Weighted Regression
This lab is somewhat of an extension of last week's, which dealt with Ordinary Least Squares (OLS) regression. OLS regression is a numeric or non-spatial analysis that predicts values of a dependent variable based on independent, or explanatory, variables. The main thing is that with OLS regression, all the values are given the same weight when predicting the dependent variable's values. This week with Geographically Weighted Regression (GWR), we learned how to perform the same type of analysis, but now the analysis is weighted in that areas that are spatially closer to a particular point for which we are trying to predict are given more weight than areas farther away. GWR allows us to analyze how the relationships between the explanatory variables and the dependent variables change over space.
The first part of the lab has us using the data from last week's lab on OLS and performing a GWR analysis using the same dependent and independent variables. We were then to compare the two analyses to determine which was better. In this case, GWR gave a higher adjusted R-squared value and a lower AIC value, so GWR was better.
In the second part of the lab, we were to complete a regression analysis (both OLS and GWR) for crime data. For the analyses, I needed to select a type of high volume crime, so I chose auto theft. After joining the auto theft and the census tract fields, I added a new Rate field, as crime data statistics are investigated using rates instead of raw counts. I created a correlation matrix with Escel using the 5 independent variables in the lab:
BLACK_PER - Residents of black race as a % of total population
HISP_PER - Residents of Hispanic ethnicity as a % of total population
RENT_PER - Renter occupied housing units as a % of total housing units
MED_INCOME - Median household income ($)
HU_VALUE - Median value of owner occupied housing units ($)
These coefficients are basically a measure of the strength of the linear relationship between that independent variable and our dependent variable, in this case the rate of auto thefts per 10,000 people. Based on the correlation matrix, I chose to use median income, renter occupied housing, and black population percentage as my 3 independent variables. I did not use variables where the correlation coefficient was very nearly 0. I also did not use both variables with negative coefficients, as they were strongly correlated with each other, so I used only the variable that was more strongly negatively correlated with the dependent variable. Using ArcGIS, I performs an OLS analysis and used Moran's I to determine the spatial autocorrelation between the residuals. I ran into an issue here where based on Moran's I, the data was clustered (z-value of over 9). Often that is a sign that not enough independent variables were included in the analysis, so I ran it a couple more times using more and fewer independent variables, but the clustering remained, so I went with my original 3 independent variables based on both the correlation matrix and the statistically significant p-values. The adjusted R-squared value here is much lower than what I am used to seeing from last week and the first part of this lab (0.220) and the OLS had an AIC of 2514.415.
I then performed a GWR analysis using the same dependent and independent variables. There was an improvement in the adjusted R-squared (0.300) and AIC (2471.306) values, but the most dramatic improvement was when I performed Moran's I and found a z-score for residuals of -1.073, which means the data is no longer clustered and is now randomly distributed. I think the adjusted R-squared values are so low because none of the independent variables showed a really strong correlation to the auto theft rate (most of the values were around 0.4 or 0.5). If there isn't a strong correlation, there must be another factor not included in the analysis leading to the auto theft rate.
I'm not necessarily sure that either analysis is the best for predicting the rate of auto thefts, primarily due to the adjusted R-squared values. The best I could manage was 0.300, which means that 30% of the spatial variation in auto thefts per 10,000 people can be explained by the 3 independent variables used. The results were that in the center of the map the observed values of auto theft were higher than the predicted values (over 2.5 standard deviations in a couple of spots), and observed values were slightly lower than predicted a little further west and north of center. Over the rest of the map, the observed and predicted values were very similar. A better result might come from using different or more independent variables (perhaps something similar to distance from urban centers such as in last week's lab), or from a different type of analysis.
Overall, I feel I have a better understanding of what these regression techniques are telling us, and a better idea of what to do to get better results. I feel I understand GWR better than OLS for some reason; maybe it's that the concept of closer objects being more related than objects farther away, which is the basic premise behind GWR, makes sense to me.
The first part of the lab has us using the data from last week's lab on OLS and performing a GWR analysis using the same dependent and independent variables. We were then to compare the two analyses to determine which was better. In this case, GWR gave a higher adjusted R-squared value and a lower AIC value, so GWR was better.
In the second part of the lab, we were to complete a regression analysis (both OLS and GWR) for crime data. For the analyses, I needed to select a type of high volume crime, so I chose auto theft. After joining the auto theft and the census tract fields, I added a new Rate field, as crime data statistics are investigated using rates instead of raw counts. I created a correlation matrix with Escel using the 5 independent variables in the lab:
BLACK_PER - Residents of black race as a % of total population
HISP_PER - Residents of Hispanic ethnicity as a % of total population
RENT_PER - Renter occupied housing units as a % of total housing units
MED_INCOME - Median household income ($)
HU_VALUE - Median value of owner occupied housing units ($)
These coefficients are basically a measure of the strength of the linear relationship between that independent variable and our dependent variable, in this case the rate of auto thefts per 10,000 people. Based on the correlation matrix, I chose to use median income, renter occupied housing, and black population percentage as my 3 independent variables. I did not use variables where the correlation coefficient was very nearly 0. I also did not use both variables with negative coefficients, as they were strongly correlated with each other, so I used only the variable that was more strongly negatively correlated with the dependent variable. Using ArcGIS, I performs an OLS analysis and used Moran's I to determine the spatial autocorrelation between the residuals. I ran into an issue here where based on Moran's I, the data was clustered (z-value of over 9). Often that is a sign that not enough independent variables were included in the analysis, so I ran it a couple more times using more and fewer independent variables, but the clustering remained, so I went with my original 3 independent variables based on both the correlation matrix and the statistically significant p-values. The adjusted R-squared value here is much lower than what I am used to seeing from last week and the first part of this lab (0.220) and the OLS had an AIC of 2514.415.
I then performed a GWR analysis using the same dependent and independent variables. There was an improvement in the adjusted R-squared (0.300) and AIC (2471.306) values, but the most dramatic improvement was when I performed Moran's I and found a z-score for residuals of -1.073, which means the data is no longer clustered and is now randomly distributed. I think the adjusted R-squared values are so low because none of the independent variables showed a really strong correlation to the auto theft rate (most of the values were around 0.4 or 0.5). If there isn't a strong correlation, there must be another factor not included in the analysis leading to the auto theft rate.
I'm not necessarily sure that either analysis is the best for predicting the rate of auto thefts, primarily due to the adjusted R-squared values. The best I could manage was 0.300, which means that 30% of the spatial variation in auto thefts per 10,000 people can be explained by the 3 independent variables used. The results were that in the center of the map the observed values of auto theft were higher than the predicted values (over 2.5 standard deviations in a couple of spots), and observed values were slightly lower than predicted a little further west and north of center. Over the rest of the map, the observed and predicted values were very similar. A better result might come from using different or more independent variables (perhaps something similar to distance from urban centers such as in last week's lab), or from a different type of analysis.
Overall, I feel I have a better understanding of what these regression techniques are telling us, and a better idea of what to do to get better results. I feel I understand GWR better than OLS for some reason; maybe it's that the concept of closer objects being more related than objects farther away, which is the basic premise behind GWR, makes sense to me.
Tuesday, November 10, 2015
Lab 10 - Supervised Classification
In this lab, we learned how to perform supervised classification on satellite imagery. We learned to create spectral signatures and AOI features and to produce classified images from satellite data. We also learned to recognize and eliminate spectral confusion between spectral signatures.
In the first part, we learned to use ERDAS Imagine to perform supervised classification of image files. We learned to use Signature Editor and create Areas of Interest (AOIs) in order to classify different land use types. One thing I liked about this was the ability to use the Inquire tool to click on an area where we know the land use type, and then use the Region Growing Properties window at Inquire to select an area matching that land use type, and I found it is more accurate than drawing a polygon signifying a land use type. Adjusting the Euclidean distance to get the best results is somewhat tricky and I could use a little more practice with it, but I think I get the general idea that it signifies the range of digital numbers (DN) away from the seed that will be accepted as part of that category.
We also learned to evaluate signatures histograms to determine if they are spectrally confused, which occurs when one signature contains pixels belonging to more than one feature. To check this in the histogram, we select two or more signatures and compare the values in a single band. If the two signatures overlap, they are spectrally confused, which causes problems when reclassifying the image. We can look at the spectral confusion of all the signatures by viewing the mean plots. If bands are close together, spectral confusion could be a problem.
In Exercise 3, we learned to classify images, and there are various options. In this case, we are using the Maximized Likelihood classification, which is based on the probability that a pixel belongs to a certain class. This process also creates a distance file, which is very interesting, as the brighter pixels signify a greater spectral Euclidean distance. So the brighter the pixel, the more likely that pixel is misclassified, and this helps determine when more signatures are required to obtain a good classification. We also learned to merge the classes, which is basically using the Recode tool that we learned to use last week, in which we merge all like signatures into one signature (i.e. merging 4 residential signatures into 1).
In the final portion of the lab, we are reclassifying land use for the area of Germantown, Maryland in order to track the dramatic increase in land consumption over the last 30 years. Initially, I used the Drawing tool to draw polygons at the Inquire points, but I wasn’t getting a good classification result, so I went to creating the signatures from the “seed” point, using the Inquire point as the seed points. I created the signatures based on the coordinates in the lab and used the histogram to attempt to use bands with little spectral confusion. Based on the histogram and the mean plots, I used bands 5, 4, and 6 for my image. My reclassified image is below.

I ran into some problems after recoding, as the classification is not as accurate as I had hoped. It is evident to me that many of the urban areas are misclassified as either roads or agricultural areas. The areas classified as water are classified well, as surprisingly are the vegetation layers. As they are similar spectrally I anticipated more misclassified vegetation than there are. I think the two land use classifications that are overclassified (where there are more pixels classified that way than actually are present) are roads and agriculture, and I believe that many urban/residential areas are misclassified as agriculture or roads, likely due to the similarities between the spectral signatures (possibly in band 6). I did not have time to add more signatures than detailed in the lab, and I think that would have helped my classification here. Even so, I think supervised classification is an excellent technique, and I'm glad I learned how to use it.
In the first part, we learned to use ERDAS Imagine to perform supervised classification of image files. We learned to use Signature Editor and create Areas of Interest (AOIs) in order to classify different land use types. One thing I liked about this was the ability to use the Inquire tool to click on an area where we know the land use type, and then use the Region Growing Properties window at Inquire to select an area matching that land use type, and I found it is more accurate than drawing a polygon signifying a land use type. Adjusting the Euclidean distance to get the best results is somewhat tricky and I could use a little more practice with it, but I think I get the general idea that it signifies the range of digital numbers (DN) away from the seed that will be accepted as part of that category.
We also learned to evaluate signatures histograms to determine if they are spectrally confused, which occurs when one signature contains pixels belonging to more than one feature. To check this in the histogram, we select two or more signatures and compare the values in a single band. If the two signatures overlap, they are spectrally confused, which causes problems when reclassifying the image. We can look at the spectral confusion of all the signatures by viewing the mean plots. If bands are close together, spectral confusion could be a problem.
In Exercise 3, we learned to classify images, and there are various options. In this case, we are using the Maximized Likelihood classification, which is based on the probability that a pixel belongs to a certain class. This process also creates a distance file, which is very interesting, as the brighter pixels signify a greater spectral Euclidean distance. So the brighter the pixel, the more likely that pixel is misclassified, and this helps determine when more signatures are required to obtain a good classification. We also learned to merge the classes, which is basically using the Recode tool that we learned to use last week, in which we merge all like signatures into one signature (i.e. merging 4 residential signatures into 1).
In the final portion of the lab, we are reclassifying land use for the area of Germantown, Maryland in order to track the dramatic increase in land consumption over the last 30 years. Initially, I used the Drawing tool to draw polygons at the Inquire points, but I wasn’t getting a good classification result, so I went to creating the signatures from the “seed” point, using the Inquire point as the seed points. I created the signatures based on the coordinates in the lab and used the histogram to attempt to use bands with little spectral confusion. Based on the histogram and the mean plots, I used bands 5, 4, and 6 for my image. My reclassified image is below.

I ran into some problems after recoding, as the classification is not as accurate as I had hoped. It is evident to me that many of the urban areas are misclassified as either roads or agricultural areas. The areas classified as water are classified well, as surprisingly are the vegetation layers. As they are similar spectrally I anticipated more misclassified vegetation than there are. I think the two land use classifications that are overclassified (where there are more pixels classified that way than actually are present) are roads and agriculture, and I believe that many urban/residential areas are misclassified as agriculture or roads, likely due to the similarities between the spectral signatures (possibly in band 6). I did not have time to add more signatures than detailed in the lab, and I think that would have helped my classification here. Even so, I think supervised classification is an excellent technique, and I'm glad I learned how to use it.
Subscribe to:
Posts (Atom)