The MAUP is impacted by two components: the scale effect and the zonation effect. The scale effect is attributed to the variation in numerical results owing strictly to the number of areal units used in the analysis. The zonation effect is attributed to the variation in numerical results owing strictly to the manner in which a larger number of smaller areal units are grouped into a smaller number of larger areal units.
First, we were to examine the relationship between poverty and race using different geographic units, ranging from large numbers of small in area units (original block groups) to small numbers of units large in geographic area (House voting districts and counties). After doing this, the general pattern was that lower poverty percentages correlated with a small percentage of non-white residents. As the percentage of non-white residents, the poverty level tended to increase. As discussed in the lecture and readings, the correlation increased with smaller sample size as demonstrated by the increase in the R-square values. Not only can the number of polygons change the results, but also the area that each polygon covers can change the numerical results when comparing the census variables. The key to minimizing the impact of the MAUP on any analysis is to be consistent both in the geographical size and the number of areal units used.
Next we investigated the MAUP in the context of gerrymandering, which is to manipulate district boundaries in order to favor one political party or another. We wanted to determine which existing congressional districts deviate from an ideal boundary (i.e. which have been drawn in the context of gerrymandering the most) based on two criteria: 1) Compactness, i.e. minimizing bizarre shaped legislative districts, and 2) Community, i.e. minimizing dividing counties into multiple districts.
To measure compactness, I found a “compactness ratio” online that describes
compactness as the area divided by the square of the perimeter. After doing
this in ArcGIS, I see that values with a higher compactness ratio are districts
that have a more geometric shape (i.e. rectangles and squares) and those with
lower values are abnormally shaped districts. The compactness ratio seems to be
a 2D version of the isoperimetric inequality, which is a geometric inequality
relating the square of the circumference of a closed curve in a plane and the
area of the plane it encloses. Larger ratio values describe a smooth or
contiguous shape. For example, the rectangular state of Wyoming appears to be
one congressional district and has one of the highest values for “compactness
ratio”. An example of one of the "least compact" districts seen below.
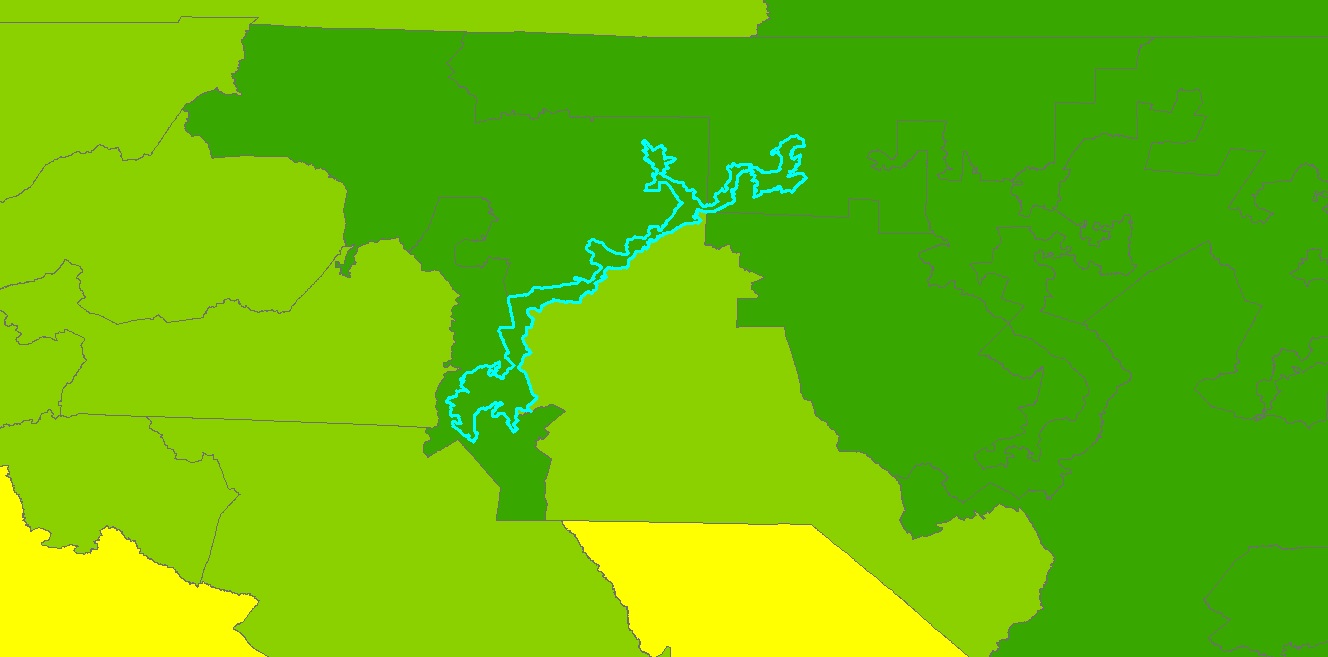
As you can see, this district is a bizarre shape. It's very long and skinny and has a lot of curves, kinks, and strangely shaped boundaries.
To measure community, I want to find areas in which one district encompasses an
entire county, not necessarily only that county, but we want counties that are
not broken up by congressional district boundaries. I had trouble with this part, as I was able to determine the number of districts within each county using a union and a spatial join, which shows the extent to which some counties are broken up into several districts, but I'm not sure this is the entire answer. Below is an image of Los Angeles County, CA, the county with the most congressional districts (24).



